
How to work with Substack export and see real readers
How to Understand Real Readers, Platform Noise, and What Actually Remains Yours

How to Understand Real Readers, Platform Noise, and What Actually Remains Yours
Note to the reader
This text is an instruction.
After reading it, the most common reaction is:
“yes, that’s exactly how it is” —
and “there’s nothing new here; I already knew this.”
This reaction is expected.
The text does not introduce new ideas.
It fixes what is already known as structure.
It examines Substack as an architecture, not a platform.
Reading here is not defined by channel
(email, app, or website),
but by the email address as the only stable binding of a reader.
Without this binding, it is impossible to distinguish
a reader from an observer.
I. What Breaks in the Author’s Perception
Almost every author encounters the same fracture:
many comments → a feeling of support;
likes and replies → a sense that the text was read;
feed activity → a sense that the post is “alive.”
But when this is compared to actual reading, a mismatch appears. Comments exist, but email reads do not. Activity is high, but the core remains quiet.
This is not an author’s mistake. It is a consequence of platform architecture.
In this text, reading is not considered as a fact of access.,
and as an event that can be associated with an address, text and time.
Paid Readers: How the Platform Reshapes the Author
There is a second, more subtle layer to this fracture: paid subscribers.
Substack structurally rewards authors for paid subscriptions.
The interface highlights them. Dashboards foreground revenue. Notifications reinforce the signal.
This is not about the intentions of the authors,
but about a statistically stable distortion of attention.
Over time, this produces a quiet but powerful shift.
Paid readers begin to feel like:
confirmation of value;
proof of legitimacy;
justification for continuation.
And something else happens.
The author’s attention bends.
Without intending to, the author begins to:
write for paid readers;
protect them from discomfort;
stabilize tone, themes, and frequency to prevent withdrawal;
avoid risks that might cause paid readers to leave.
This is not corruption.
It is conditioning.
The platform does not merely host writing.
It trains authors through visible reward loops.
As a result:
paid readers gain disproportionate gravitational pull;
silent readers recede even further into invisibility;
the address gradually narrows.
Export is the only place where this distortion becomes measurable.
In the data, paid readers are simply email addresses with events.
They do not inherently represent depth, understanding, or continuity.
Confusing payment with reading collapses authorship into service.
Growth Is Not Support: How Algorithms Actually Work
Growth is not courage.
It is not risk.
And it is certainly not belief.
Growth is mechanical.
It follows gravity, not intention. Platforms reward trajectories, not virtue.
What looks like support is often a low-risk alignment with an emerging vector.
When an account is small, gestures of attention feel personal.
When growth begins, those same gestures retroactively become stories of loyalty.
This is not altruism.
It is field mechanics.
Algorithms amplify what already shows directional consistency.
They do not respond to kindness, encouragement, or mutual affirmation.
They respond to:
sustained publication rhythm;
coherent thematic signal;
reader retention over time;
predictable engagement density.
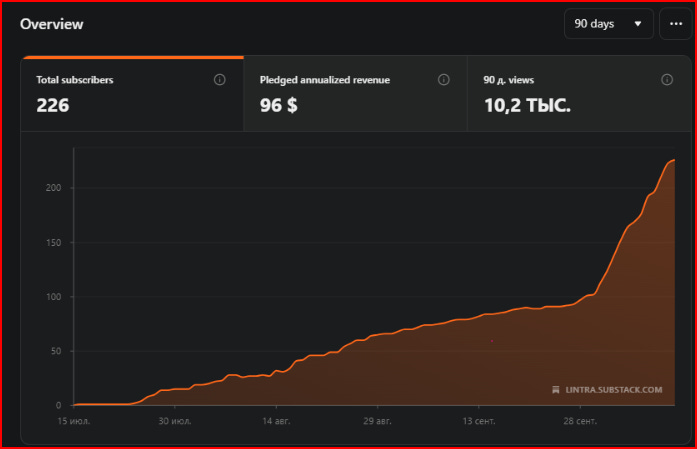
At some point, acceleration occurs.
It looks sudden — but it is not.
This moment is often misread as communal support or collective belief.
In reality, it marks the point at which the system has enough data to reduce risk.
The graph changes.
The author feels lifted.
But nothing relational has changed.
What grows is visibility — not intimacy.
Understanding this distinction protects the author from rewriting their own history as a moral tale.
Growth is not good or bad.
It is a consequence of alignment between writing, readers, and algorithmic recognition.

Oct 13, 2025
II. Substack as Several Irreducible Layers
Substack is not a single environment. It is at least five different realities:
Feed and post card (the public stage)
Notes as a platform overlay
Email delivery as an autonomous channel
Dashboard analytics as an aggregated showcase
Data export as an event layer
The error begins when these layers are perceived as the same. They are not equal and do not convert into one another.
III. What the Substack Export Actually Contains
A full Substack export includes several CSV files. The key ones are:
posts.csv — the content registry, the axis of publication time.
email_list.csv — the subscriber list. This is not about reading, but about contract: who is allowed to receive emails.
opens.csv — email open events. The most important file. It records which email opened which post_id and when.
This file alone makes it possible to talk about real reading rather than impressions.
IV. Why Analysis Does Not Exist Without Linking Files
No single file has meaning on its own.
posts.csv without opens is a list of texts without readers;
email_list.csv without opens is a list of addresses without reading;
opens.csv without posts is a set of events without context.
Analysis begins only when these files are linked via post_id and email. Manual work at this scale is unrealistic — this is where AI is needed as a structuring tool, not an interpreter.
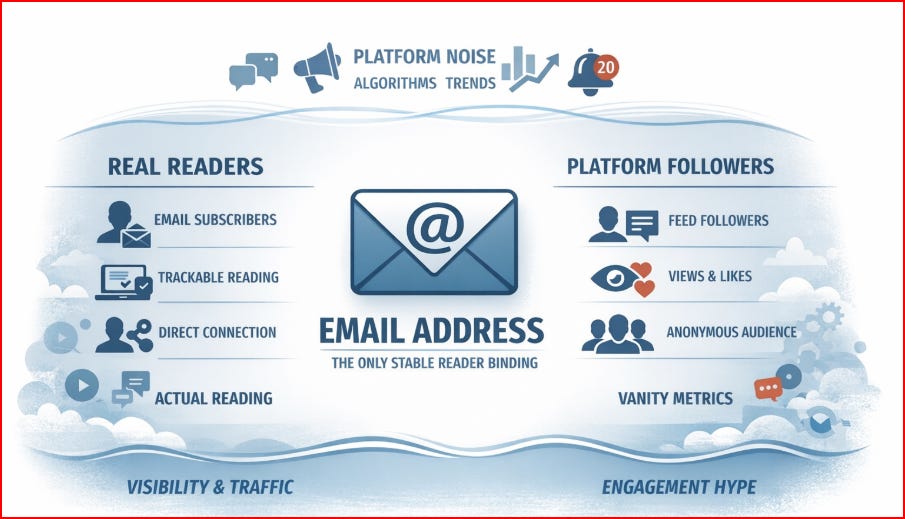
V. Reader and Follower: Fundamentally Different Figures
This distinction is central.
In the Substack interface, readers and followers look identical. The same icon. The same “follow” label. The same visual signal of presence.
Follower
A follower is a platform user.
They:
clicked follow in the feed or via a recommendation;
may see posts in the feed;
may like or comment;
may create a sense of activity;
are not required to be subscribed to email;
are not required to read the text;
may never open an email at all.
Followers exist inside the platform. Their actions strengthen the algorithm, not the address.
Reader
A reader is an email address.
They:
subscribed to the newsletter (often without a Substack account);
receive the text directly;
read outside the feed and the stage;
may never comment;
may be completely invisible publicly;
exist only in opens.csv.
Readers exist outside the platform, even if the text originates there.
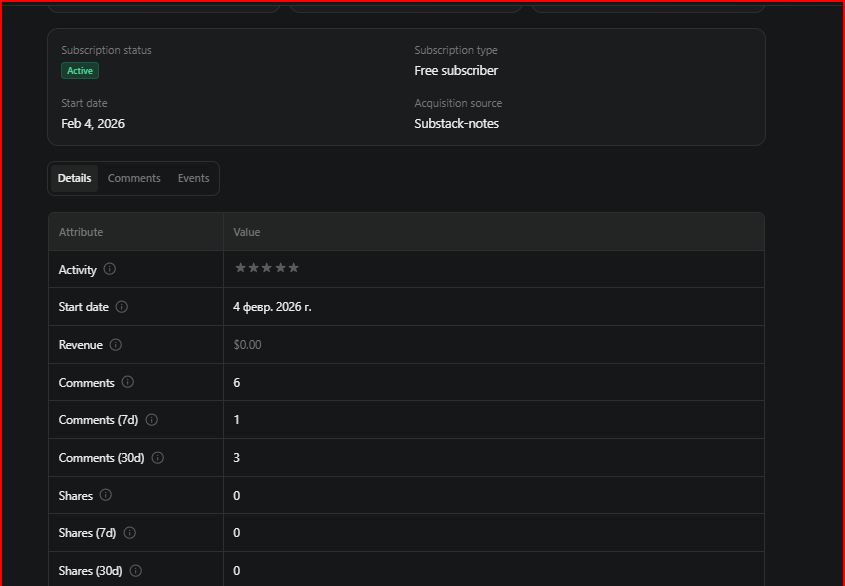
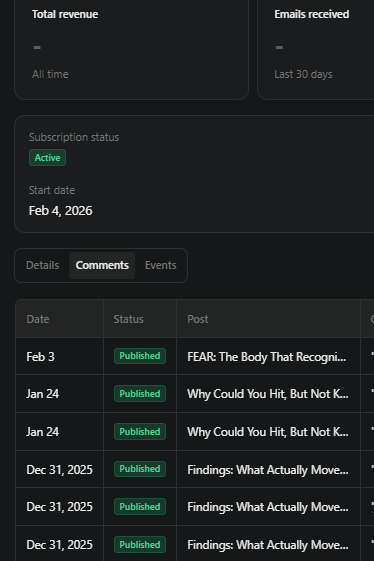
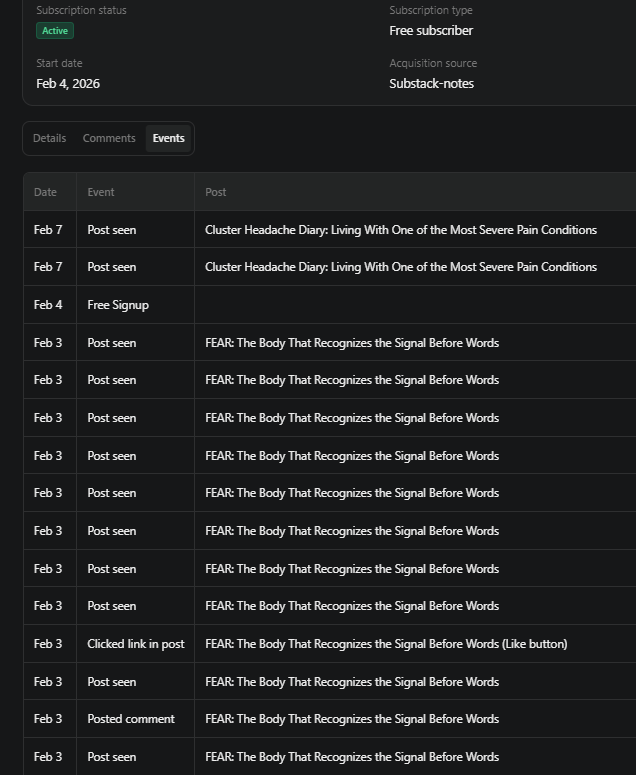
below is a screenshot of one reader’s card

VI. Why the Interface Hides This Distinction
Substack deliberately does not separate these roles visually.
If authors clearly saw that:
active commenters ≠ readers;
most reading happens via email;
noise does not convert into address;
they would stop servicing the feed.
This is not a bug. It is design.
VII. Why Most Comments Are Not for the Author
A comment is a social gesture. It is visible, public, and instantly rewarded with attention.
In social environments, most comments are not addressed to the author.
They are addressed to:
other commenters;
the commenter’s own audience;
the platform algorithm;
the feed as a stage;
self‑fixation (“I was here”).
This is not cynicism. It is social mechanics.
Reading email offers no such reward. It is private, invisible, and therefore structurally different.
When an author equates comments with reading, they begin servicing the stage rather than the text. Export is the only place where this substitution becomes visible.
VIII. Why This Is So Hard for Authors to Accept
This distinction almost always meets resistance.
Not because authors are naive, but because human attention is structured like the interface:
what is visible feels more important;
reaction feels like contact;
the stage feels more real than the letter.
Export does not destroy an illusion of success. It destroys an illusion of control.
IX. Open Rate and Metric Misunderstanding
Open rate is not a measure of textual quality. It is the ratio of opened emails to delivered emails.
A stable 20–30% open rate with a consistent core is a healthy pattern. Spikes are often noise, not depth.
X. What the Dashboard Shows — and What It Cannot
The dashboard displays subscriber cards and aggregated activity. This creates an illusion of completeness.
But it cannot:
link specific readers to specific posts;
show reading sequences;
distinguish texts by core readership;
reveal what actually sustains the address.
The dashboard answers “what happened.” Export answers “who reads, and how.”
XI. Why This Analysis Exists at All
Export is not about curiosity or control. It is about authorship.
It answers three fundamental questions:
Where does my text actually reside — with me or with the platform?
Who constitutes stable reading, and who produces only presence?
What disappears if the platform becomes inaccessible?
XII. Texts Inside the Export
Export contains not only people, but texts.
Full export includes:
HTML versions of published posts;
post metadata;
delivery structure.
Your texts physically exist outside the platform — if you take them.
Substack is not a library. It is a publisher.
XIII. Unsubscribes: The Blind Zone
Unsubscribe notifications provide emotion without context.
Export provides history. It allows you to see whether a core reader left or whether noise fell away. These are not equivalent events.
XIV. What Happens When an Account Is Blocked
Blocking does not always mean deletion. It means loss of control.
You lose interface access, analytics, and audience management. Export determines whether anything remains with you.
XV. What Export Ultimately Provides
Export gives four things:
Ownership of text
Ownership of address
Distinction between reader and noise
Possibility of continuation
XVI. Instead of a Conclusion
Platforms change. Interfaces disappear.
Letters remain only where reading does not need to be visible — and where the author keeps their own archive.
The next text will be purely technical: how to work with Substack export without turning analysis into another dependency.
If you’ve experienced bans, glitches, or disappearing readers — speak. This is not an isolated experience.
Growth makes visibility louder — export is what lets you hear whether anyone is actually reading.
Legal Notice
All algorithm-related analyses published here are original works based on the author’s independent research and observation.
No third-party analytical frameworks or proprietary materials are used.
Any similarity of conclusions reflects independent analysis of the same systems.
Technical Protocol: How to Work with Substack Export
Everything below can be copied directly into an AI tool and used as-is.
This is not a guide for manual analysis. It is a protocol for delegating correct work to an AI without distortion, simplification, or platform-driven bias.
This protocol reflects one valid analytical method and does not claim exclusivity.
What This Block Is For
This technical block exists for one purpose only:
to extract the real structure of reading from Substack export data without confusing it with visibility, activity, or social noise.
It assumes:
you already understand the distinction between reader and follower;
you are not optimizing for growth or engagement;
you are working with export as a protection and clarification tool.
What You Need Before You Start
A full Substack export, including at minimum:
posts.csvemail_list.csvopens.csv
Optional but useful:
HTML files of posts (for archiving and migration)
Do not start if you only have dashboard screenshots.
Core Rule (Non‑Negotiable)
Never analyze Substack export manually.
Manual reading of opens.csv is structurally impossible at scale and guarantees false conclusions.
The export must be processed as linked data.
Mandatory Setup Before Running the Analysis
This block must be used in full. Do not shorten, rewrite, or adapt it.
Before running any analysis:
Upload all export files at once (
posts.csv,email_list.csv,opens.csv).Paste the entire prompt below as a single block.
Do not add your own questions until the model completes all steps.
Partial prompts or missing files invalidate the results.
Universal AI Prompt for Substack Export Analysis
You can paste the following prompt directly into any AI tool that supports CSV uploads.
ROLE:
You are a data‑analysis instrument. Do not interpret psychology, motivation, or intent. Do not give growth advice. Work only with the uploaded files.
DATA PROVIDED:
I am uploading Substack export files:
- posts.csv (post_id, publication dates, metadata)
- email_list.csv (email, subscription status, subscription date)
- opens.csv (email, post_id, timestamp)
OBJECTIVE:
Extract the structural pattern of reading.
MANDATORY RULES:
- Use post_id as the primary key for content.
- Use email as the identifier for a reader.
- Treat email opens as reading events.
- Ignore comments, likes, notes, web traffic, and dashboard metrics.
- Make no assumptions beyond what the data supports.
TASKS:
STEP 1 — DATA VALIDATION
Confirm available columns in each file.
Report missing or inconsistent fields.
STEP 2 — DATA LINKING
Link opens.csv to posts.csv via post_id.
Link opens.csv to email_list.csv via email.
Confirm successful linkage.
STEP 3 — READER SEGMENTATION
For each email:
- count number of unique post_id opened
- calculate percentage of opened posts relative to total sent in the selected period
Segment readers into:
- CORE_READERS (≥70% of posts opened)
- OCCASIONAL_READERS (20–69%)
- INACTIVE (<20%)
STEP 4 — POST ANALYSIS
For each post_id:
- count unique emails that opened it
- count how many of those belong to CORE_READERS
- calculate core‑reader share
STEP 5 — STRUCTURAL CLASSIFICATION
Classify posts as:
- CORE_TEXTS (high core‑reader share)
- DISTRIBUTION_TEXTS (high opens, low core share)
- EDGE_TEXTS (mixed response)
OUTPUT REQUIREMENTS:
- Tables only, no narrative speculation
- Clear counts and percentages
- Separate sections for readers and posts
How to Read the Output (Important)
Do not look for optimization advice.
You are looking for:
stability of CORE_READERS over time
consistency of CORE_TEXTS
separation between visibility and reading
If the core is stable, the system is working.
What Not to Ask the AI
Never ask:
why people unsubscribed
why a post failed
how to grow faster
how to increase engagement
These questions produce fiction, not structure.
Archiving and Protection (Non‑Optional)
In parallel with analysis:
store HTML versions of all posts locally
keep CSV exports in dated folders
repeat export regularly
Export is not analytics.
Export is ownership.
Final Constraint
If the AI starts offering advice, interpretation, or motivation — stop it.
The task of this block is clarification, not reassurance.
This block is designed to be embedded directly into an article or documentation. No simplification is required.
When to Say STOP to the Model
AI becomes harmful the moment it crosses from structure extraction into interpretation.
You must explicitly stop the model when it begins to:
explain reader motivation;
speculate about emotions or intent;
suggest content changes;
propose growth, optimization, or engagement tactics;
reframe results as advice.
Use a hard interrupt:
STOP. Return to data only. Tables and counts. No interpretation.
If the model cannot comply, discard the output.
Using Export to Understand Topics (Not Trends)
Export does not tell you what is “popular.” It tells you what is endured.
Correct questions:
Which posts are consistently opened by CORE_READERS regardless of topic?
Which topics attract many opens but low core-reader share?
Which themes cause core stability rather than spikes?
Ignore:
viral spikes;
recommendation-driven bursts;
comment-heavy posts.
Topics that retain the core define your real field of writing.
Titles: What Export Can and Cannot Tell You
Export can tell you:
which titles are opened by the same readers repeatedly;
which titles bring new opens without retention;
which titles correlate with long-term core stability.
Export cannot tell you:
why a title worked;
how to “improve” wording;
what will work next time.
Titles are signals, not levers.
Timing: When to Publish
Use export only to detect reading rhythms, not optimal posting times.
Valid questions:
At what hours do CORE_READERS open emails most frequently?
Are there stable windows across weeks?
Invalid questions:
What time gets more clicks?
How to maximize opens?
You are aligning with an existing rhythm, not creating one.
Publication Frequency: Setting a Sustainable Schedule
Export answers one question:
Does the core remain stable at this frequency?
Signs frequency is too high:
declining core-reader percentage;
increasing partial opens;
delayed opening patterns.
Signs frequency is sustainable:
consistent core opens;
unchanged reading latency;
minimal churn in CORE_READERS.
Frequency is a structural constraint, not a growth tactic.
What Export Will Never Give You
Export will never provide:
content strategy;
audience psychology;
predictive success;
guarantees.
Attempting to extract these will destroy the signal.
Author Effectiveness Protocol: Writer vs Content Marketer
This distinction is non-optional.
Export analysis produces radically different conclusions depending on who you think you are while reading it.
Mode A — Author as Content Marketer
In this mode, export is interpreted as a performance dashboard.
The implicit questions are:
Which topics convert?
Which titles attract?
Which timing increases opens?
How do I scale attention?
Export is not built to answer these questions.
Attempting to force it into this role results in:
chasing distribution texts;
privileging spikes over stability;
confusing followers with readers;
optimizing visibility at the cost of address.
If you read export this way, it will push you toward platform compliance.
Mode B — Author as Writer
In this mode, export is read as a structural instrument.
The operative questions are:
Does my core remain intact?
Which texts are endured, not amplified?
Where does reading stay silent but stable?
At what point does frequency or tone damage continuity?
Here, export functions as:
a boundary, not a lever;
a limiter, not an accelerator;
a protection against misreading noise as audience.
This mode preserves authorship.
Switching Modes (Critical Warning)
You cannot safely switch modes mid-analysis.
Reading export as a marketer for one decision and as a writer for another produces incoherent strategy and tonal drift.
Choose the mode before opening the files.
Effectiveness Criteria by Mode
Content Marketer:
growth velocity
reach expansion
conversion rate
Writer:
core stability
reading continuity
resistance to noise
Export only reliably supports the second set.
Final Technical Boundary
If analysis produces urgency, anxiety, or a desire to “fix” content — stop.
Correct export analysis produces:
clarity;
restraint;
slower decisions;
fewer changes.
Anything else is platform noise leaking back in.
This article is the canonical entry point for the Substack Algorithms and Discovery research series.
Research hub: https://lintra.substack.com/publish/post/184858326?back=%2Fpublish%2Fsettings%23Pages
All texts in this series analyze how Substack algorithms, recommendation systems, and discovery mechanisms distribute and rank content on the platform.

Substack Data Breach Notice (Feb 2026): Email Is Sovereignty — Here’s What’s Exposed and What To Do
12) INTERNAL LINKS
The Bestseller Substack’s Illusion: When an Author Becomes an Anomaly
Findings: What Actually Moves Substack Now — Viral Chat Mechanics
How Substack Really Works: Core Audience, Metrics, and Silent Readers Explained
Participation vs Your Writing Line: Why Substack Engagement Can Weaken the Work
How Substack Really Works: Core Audience, Metrics, On conversion, silence
Chats, Notes, Recommendations — and the Quiet Cost of Being Everywhere on Substack
How to Build a Complete SEO Package for Substack (Without Losing Your Mind)
Results of 5 Months on Substack: A Forensic Analysis of Attention, Metrics, and Hidden Cost
Copyright & Authorship
© Lintara, 2026. All rights reserved.
This text is an original work authored by Lintara.
All rights to the text, structure, and analytical framework belong to the author.
No part of this article may be reproduced, republished, translated, adapted, or redistributed — in whole or in part — without explicit written permission from the author, except for brief quotations with clear attribution.
This work is published independently and is not affiliated with, endorsed by, or produced in partnership with Substack or any other platform mentioned.
Any analytical methods, frameworks, or protocols described herein are provided for informational purposes only and remain the intellectual property of the author.
I almost never open an email notification from Substack; I scroll down my subscription page instead, which means I read all of these posts without ever opening the email. I cannot help but think there are other Substackers who do the same thing.
Thanks for the excellent information on the algorithms. My primary purpose here isn't to make a living, but to teach, learn, and just have some fun. Of course I want to expand my audience, and I see that happening in the follower count, and thanks to your information I now have a better understanding of Substack's stats.
I feel like a student in an online course, whose teacher tracks if I’ve opened the materials (and read them!) before heading to the exam😰…
Ms Lintara, I’ve read them all. 🤥Please give me 💯😍